An Overview of Search Tools
Most online "searching tools" can be categorized as either a subject
tree, search engine, or virtual library. In order to be successful in your
searches, it is important to always know which kind of online resource you are using. This
page provides a brief overview to explain the differences between these
types of search
tools. |
 |
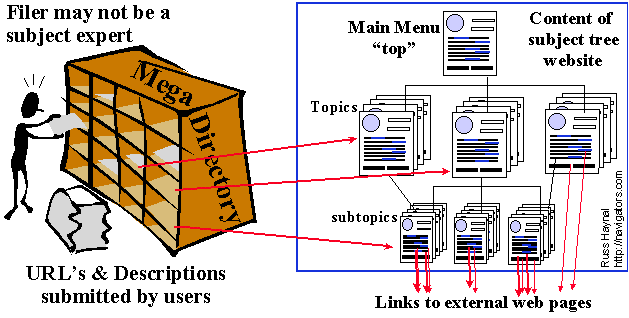
A directory is a subject-oriented index to many thousands of Internet sites. You
begin at a high level of subject area, and usually browse your way down to topics and
sub-topics.
From an initial menu, you must decide "where" your desired subject might be
listed. As you select menu items, you will notice that you are going "deeper"
down a menu hierarchy. (look at the URL’s in the browser's address box) Eventually, you
will reach a "bottom page" in the hierarchy. The bottom web page contains the
hyperlinks that will take you away from the subject tree web site to the specific web
sites containing your desired subject. The bottom page also contains the
title of the website, and a 1-sentence description of the entire website.
A directory may offer a "search" option. Recognize that this is not a
"search of the Internet", but rather a keyword search of the web pages contained
within the directory. Remember that most directory web pages contain only
the words: "name of subject", "names of subtopics", "names
of sub-subtopics",
"brief description of XYZ website". Therefore keep your search terms at a
directory at the appropriate level of detail (e.g. search for a
subject)
Note that most directories are manually built, usually from user
submissions. If someone creates a web site, and they want to be "found", they
should be sure to announce themselves to directories such as
dmoz.org.
 |
Search Engines- Key Features
- Robot explores Internet via discovered hyperlinks
- Full text copy of web pages often retrieved
- Massive database is collected/indexed
- Key word searches may yield many thousands of "hits"
|
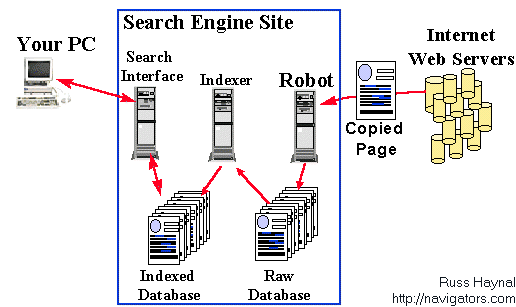
Search engines are usually characterized by very large indexed databases, which contain
pointers to millions of URL’s. Search engines have two main functions that
distinguish them from each other. Here is
a video from Google
describing how search engines work.
Building the index. Many search engines develop their vast databases by using a
software application to automate the exploration of the Internet. These applications
(known as robots, spiders, and crawlers) visit web pages, copies them into a local
database, and then explores all the links referenced in the freshly copied page. In this
manner, the search engine may eventually discover many clickable web pages, so long
as they are pointed to from someone else’s page. (You can also "invite" the
search engine to explore your site) Search engines will NOT copy web pages
if they are designated as off-limits by the web site author. See
robottxt for more information, and a list
of known robots crawlers. Example:
nytimes.com/robots.txt .
The Search Interface. As the web page information is harvested, it is
indexed and made available to the Internet through a search interface. Each search engine may contain
different options and parameters that can be used to search its database. In general, you
are performing a full keyword search against the entire text from billions of web pages.
Search engines also rank the search results in some order based on a scoring criteria. If
you use a search engine frequently, it pays to read the "help" or "advanced
search" options to learn more about how that search engine is interpreting
your queries.
Each hit includes a hyperlink to the web page and some portion of the web page’s
text. You should take the time to look at the URL’s to help decide which web page
might meet your needs before you attempt to access the page. After looking at these top
these top ten results, you can then ask for the next batch of ten , and "work"
your way through all the suggested web pages. The key to using a search
engine is visualizing the web page in your mind, and then composing a specific
enough query so that the page you envision will make it into the top 10-20-30
hits.
 |
Usually focused on a specific subject area
Often developed by “experts” in that field
or someone "without a life" |
There is an abundance of online resources and a variety of tools to seek out
information. Unfortunately, there are few of us who can afford to dedicate "their
entire life" to the task of constantly searching the Internet for the latest
information in a particular subject. Fortunately, there are other Internet users who are
able to invest such time into research their (your) topic. Probably the
single best way to thoroughly cover a topic, is to discover user pages for that topic.
User pages are subject-specific indices that are created (and maintained) by someone who
really cares about that topic.
Finding "User pages":
- Go to a directory such as DMOZ
- Browse down a couple of layers to the subject of your choice
- Usually, there is an "web directories" or "FAQ" listing for each subject
area (For example look at
section under education/colleges at Dmoz. )
- Always watch for sites labeled: “John Doe’s Ultimate guide to widgets” or
“The widget meta-site”
- Limit your search at Google or Bing to PDFs
- Search for forums/blogs - People without lives tend to hangout online
talking with people interested in the same topic
- Ask other users. Within any subject area there, is often 2-3 sites that everyone
recognizes as being the best.
- Try searching for web pages which link to several resources you have
already discovered. - For more information on this advanced technique see "surfing
upstream"
| Discussion: How to choose the right tool |
By now you are realizing just how vast the information can be on the
Internet. Search engines like Google can quickly provide you with "many" choices. A common
question at this point is; "know that we know about Google, why would we ever use
DMOZ?" DMOZ is
still quite useful when:
- You only have a general subject in mind such as "web development"
- You don’t know enough about the topic.
- You can discover related fields as you browse down the subject tree
For example, to find out about computer security, DMOZ might be your best
starting place (computers -> security) Once there, you might learn some of the
terminology (i.e. kerberos, pgp, DES) These specific words can eventually be
used at a search engines such as Google.
When starting my search , I ask myself if the topic in question is large
enough or smart enough to be announced at DMOZ. For example, If I want
the FCC web site, I am better off starting at DMOZ where I would probably
find a listing for the FCC's website. At Google, I would get 180,000,000
hits which happen to contain the word fcc.
Search engines are best used when you have very specific information you are
seeking. Since Search engines do provide different results from each other, feel
free to experiment and try different ones.

Contact me at 703-729-1757 or Russ
'at' navigators.com
If you use email, put "internet training" in the subject of the
email.
Copyright © Information Navigators